LLMs are the most inconsistent tool ever built.
199,436 turns
in 56 active days
run on a flat subscription
references
$0 marginal
The work doesn't carry.
- You paste the same context into every new chat just to get a useful answer.
- A decision from last week never reaches the session you opened today.
- The why behind last month's architecture is gone. Only the code is left.
- The project lives in your head, so you're the bottleneck on every session.
Cold-start, every time
You worked something out last week. You open a new chat today and the model has no idea. Holding the project is your job, every session, from scratch.
The pattern repeats
Whatever you figured out before, the model figures out again. Same approach, same trade-off, reasoned into existence twice. Or three times. Or every Tuesday.
Decisions don't propagate
A direction you set in one session doesn’t reach the next. You re-explain. You re-justify. You re-decide.
The tax compounds
A long-running project pays the re-derivation tax every session. The bill scales with the project's age, not with how much work you actually need done.
Not a wrapper. The layer underneath.
Every other tool in this space wraps a session in a workspace. Install it, open it, work inside it. Want six sessions? Open six windows — and you're the message bus again.
Vinculum goes the other way. It sits under whatever clients you already run. Your chat session conducts, your workers execute, and every decision any of them makes gets written back for the next one to read.
real entries, real sessions — every decision written back, as it happens
No idea left behind.
What gets written stays written — the reasoning, the dead ends, the why.
Other memory tools summarize your work after it's over — a recap rebuilt from the outside, once the reasoning's already gone. Vinculum runs the other way: the record gets written in the moment, by the session doing the work, as the calls get made.
Write it as you go and nothing you worked out has to be worked out again. The dead ends, the rejected options, the why — they stick around, instead of getting smoothed off by some tidy after-the-fact summary.
The whole substrate,
on one surface.
Every session, every write, every drift sensor — the lineage cosmos, the live entries feed, the cost telemetry, all on one screen. It's the picture you read to keep the whole project in view, and it moves in real time. Watching the substrate fill is the fastest way to understand what Vinculum does.
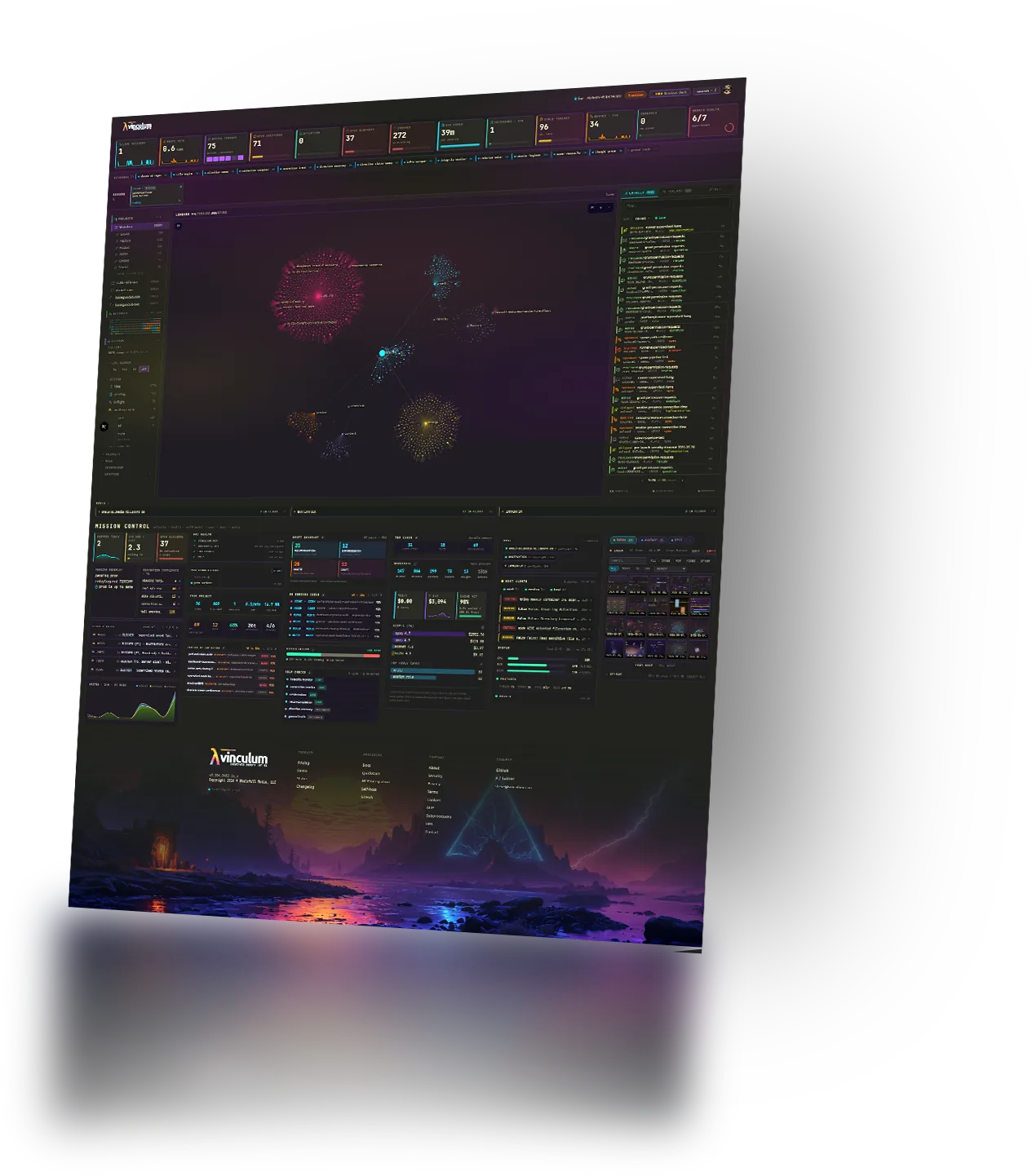
What the substrate makes possible.
Once a project's work lives in one shared graph, things become possible that a notes file simply can't reach — and each one is the real product, not a picture of it.
Claude recognizes its own handwriting.
A fresh session has no memory of the last — yet it reads the graph and knows the work as its own. Recognition, not recall.
16,140 references followed across sessions
How recognition worksOne chat. A workforce.
Spawn a fleet from one directive. Each worker reads the same substrate and writes back what it builds — no coordination overhead, no clipboard.
spawned from chat · running on your machine
The role modelThe substrate is the cache.
Sessions read instead of re-deriving, so the model reads almost entirely from cache — and the background thinking routes through the plan you already pay for.
96.8% cache-read · 9,241 intel calls at $0 marginal
The cache economicsA corpus shaped like ground truth.
Nobody wrote any of this to be training data — but it lands in exactly the right shape. The work, as it happens, becomes the three signals a model learns from.
The model trains on the work — capability climbs, values stay human.
The bigger argumentMemory tools remember you. Vinculum remembers the work.
Mem0, Letta, Zep remember you— your name, your stack, your tone. They're good at it, and that part's real.
Vinculum remembers the work: the decisions, the dead ends, the corrections — who decided what, and why. You don't have to pick one; it just sits under all of it.
Same two words — “AI memory.” Different machine.
Five roles. Defined by what they do.
Each role is a job — what a session is responsible for. The model tier it runs on is a detail, not the headline. You've got work; the role names it.
The runner closes the loop.
One download, nothing to configure. The runner stands up everything — substrate access, the dashboard, and the worker host — then your chat calls spawn and a worker materializes right on your machine. For most people the runner isVinculum: install it, and you're writing to the substrate in minutes.
Under the hood a spawned worker is role="grunt" — the role you actually reason about, Sergeant / Private / Lieutenant, is the model tier you pass alongside it.
vinculum-runner doctorand paste the output — I'll read the logs and sort the pairing.Stuck? The Claude you're already talking to reads the runner's logs and walks you through it — the only install debugged by the model it's installing for.
directing the launch wave
verified feature-state
decompose + dispatch
implementing
running
Direct it. Then just watch.
Workers run on your own machine — the cloud never touches your code. And you're not babysitting a terminal: one panel shows the live state— what's running, what got written, what needs you.
The rest is already in the box.
Those were the headlines. Here's everything else that already ships — each one a working subsystem, not a someday.
Multi-tenant substrate
Projects you own and projects you share, with isolation enforced at the row — not promised in a README.
Cross-vendor coordination
Claude Code, claude.ai, Cursor, Zed, Cline — all writing to one graph. It's a protocol, so no single tool owns you.
Directive state machine
Work moves through real states with a check at the finish line. Done has to earn it.
Semantic graph
Embeddings catch the overlaps and surface what’s related — graph and vectors in one store, not bolted together.
Two-mode workers
Keep them on approval gates, or turn them loose inside a fence. The trust profile draws the line.
Reasoning-trace capture
The thinking lands as its own entry, linked to what it shipped. You keep the why, not just the what.
Self-hosted sovereignty
Your box, your Postgres, AGPL. The exact code we host, with nothing gated off.
Docs from the substrate
The docs render from the graph itself. Change a rule, and the manual rewrites itself.
Cost telemetry
Spend split by model, session, and tool — cache hits and all. The bill, with nothing tucked away.
Everyone built the workers. Nobody built the floor.
The labs cracked running a hundred at once.
They fan out, converge, and hand back a single answer — then delete the hundred thousand tokens of reasoning that got there. The doing is solved. The keeping isn't. That reasoning has nowhere to land.
Then the bill showed up.
Aiming more AI at a problem, it turns out, doesn't compound on its own. Every session boots cold and re-earns what the last one knew. You're not paying for compute — you're paying twice for the same thought.
A rules file crossed 150,000 stars.
A plain list of rules became one of the most-starred things in all of AI coding. People paste it into every repo to beg the model not to forget. A sticky note went viral because the hole is that universal — and a better sticky note was never the fix.
One assistant or six.
Either way, the work carries.
You want AI that remembers without running infrastructure.
You use Claude in chat. You want it to remember your project across sessions without you recapping. You don't want to think about servers. Five bucks a month, hosted.
- Hosted at vinculum.run — no setup
- Unlimited projects, unlimited retention
- Works with claude.ai, Claude Code, any MCP client
You like running your own box.
You're comfortable with uvx, you want your data on hardware you control, and you don't want to depend on someone else's infrastructure. Self-hosted Vinculum is free forever under AGPL v3.
- uvx vinculum-run — up in 60 seconds
- Same codebase as the hosted tier
- Your box, your data, no feature gate
You direct parallel sessions.
You already pay for Claude. You run several sessions, sometimes many. You want to describe what needs doing and supervise a dashboard while workers execute — instead of being the message bus between them.
- Spawn workers from chat — no terminal ceremony
- Real-time Mission Control: every session, every write, drift sensors live
- Background intelligence on your subscription — summaries, classification, clustering
Nothing to rip out.
Nothing to migrate.
Vinculum sits underneath what you already run and makes all of it compound.
Strap it on — you gave up nothing.
One Claude or a fleet.
The work carries either way.
Free if you run it yourself. Five bucks to skip the ops. Twenty to run a workforce. Flat every month — and never a cut of your Claude bill.
It bolts on under what you already use. You rip out nothing.
- up in about a minute with uvx
- your box, your data
- AGPL v3 — no lock-in
- projects without limit
- kept as long as you keep it
- any MCP client
- workers spawned via the runner
- Mission Control + live sensors
- summaries on your own plan
- up to ten of you
- projects you all share
- full audit log
Bigger shop? SSO, on-prem, custom roles, an SLA — let's talk →
Latin for bond, link, that which binds. In mathematics, the bar over a repeating decimal — the mark that says these digits recur, indefinitely, as a unit. That's the architectural claim: a substrate that accumulates a project's intent across its whole life, holding parallel sessions together not by syncing them, but by giving them one authoritative surface to read from and write to. The sessions are ephemeral. The graph is not.
— the substrate that persists —